What is a K-armed Bandit ?
A gentle introduction to the fundamentals of reinforcement learning
What is a K-Armed Bandit?
The k armed bandit problem or the multi-armed bandit is as follows:
We have k slot machines and an octopus with 10 arms operating those k-slot machines (K > 10)
everytime the lever is pulled, the slotmachine gives a random reward out of a normal distribution set for that machine
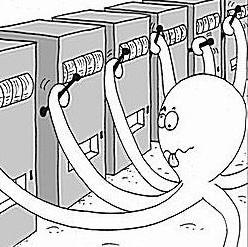
the multi-armed octopus pulling on m levers of a k slot machines
The goal here it to maximize the total reward obtained by pulling the levers of the machines
Points to be noted:
- We will not get the same reward or a reward with certainity or predictability out of the slot machines
- We do not get to pull all the K arms of the slot machines as we have only 10 arms
If a value function were to be evaluated for the K-Armed bandit test bed given by \(q^*(a)\), then \(a\) is :
- is a scalar lever number
- a vector that represents the levers pulled at time instant \(t\)